Software development is inherently uncertain. In iterative models where requirements evolve and feedback loops are frequent, the nature of risk shifts significantly compared to traditional waterfall approaches. Risk management in iterative software projects is not a one-time activity but a continuous, integrated process woven into the fabric of the development lifecycle. This guide explores how teams can identify, assess, and mitigate risks without stifling the agility that drives modern innovation.
When working in sprints or cycles, the assumption that every variable can be predicted at the outset is invalid. Instead, the focus moves to detecting signals early, adapting plans dynamically, and maintaining transparency. By treating risk as a manageable variable rather than an unexpected event, organizations can deliver value consistently while protecting the project from derailment.
Why Traditional Risk Models Fail in Agile 📉
Traditional project management often relies on a heavy upfront phase dedicated to risk identification. This involves creating comprehensive risk registers that are rarely revisited once development begins. In an iterative environment, this approach creates several friction points:
Static Documentation: A risk register created at the start of a project becomes obsolete as soon as market conditions or technical dependencies change.
Late Detection: Waiting for a formal review cycle means risks are identified only after they have already impacted the timeline or budget.
Lack of Visibility: Stakeholders often see risk management as a backend administrative task rather than a strategic necessity.
Rigid Response Plans: Pre-defined contingency plans often fail when the actual risk manifests in an unforeseen way.
In contrast, iterative risk management embraces the reality of change. It acknowledges that the unknown is the only certainty. The goal is not to eliminate all risk, which is impossible, but to reduce exposure to levels that the team can handle within the current iteration. This requires a shift in mindset from risk avoidance to risk absorption and adaptation.
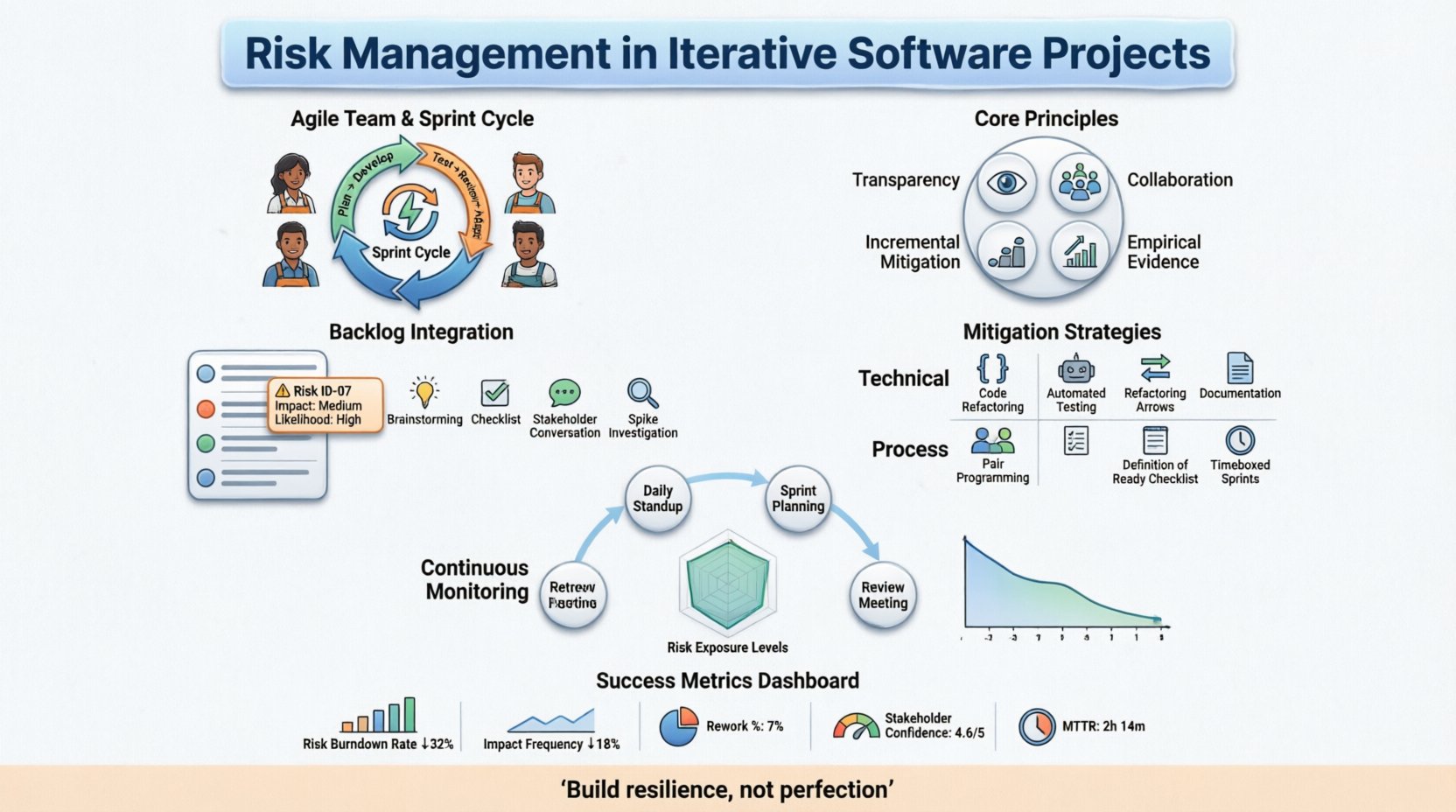
Core Principles of Iterative Risk Handling 🧠
Effective risk management in a fast-paced environment relies on a few foundational pillars. These principles ensure that safety and speed are not mutually exclusive.
Transparency: Risks must be visible to everyone involved. Hiding problems only delays the inevitable solution and erodes trust.
Collaboration: Risk identification is not solely the responsibility of a manager. Developers, testers, and product owners all bring unique perspectives on potential failure points.
Incremental Mitigation: Instead of trying to solve a complex risk in one go, break it down into smaller tasks that can be addressed within a sprint.
Empirical Evidence: Decisions regarding risk should be based on data and feedback from previous iterations, not on gut feeling or historical assumptions.
When these principles are applied, the team creates a culture where admitting uncertainty is seen as a strength. This psychological safety allows members to flag issues before they become critical failures.
Identifying Risks Within the Backlog 📝
The product backlog is the central hub for work items. Integrating risk items directly into this artifact ensures they are prioritized alongside functional features. This approach prevents risk management from becoming a separate, ignored process.
Techniques for Discovery
Identifying risks requires structured thinking. Teams can employ several methods to surface potential issues:
Brainstorming Sessions: Dedicate time during sprint planning or refinement to ask, “What could go wrong with this story?” Focus on technical debt, external dependencies, and team capacity.
Checklists: Maintain a standard list of common risk categories (e.g., security, performance, compliance) that is reviewed for every new epic.
Stakeholder Interviews: Engage with business owners to understand their risk tolerance and external pressures that might affect the project.
Technical Spikes: Use short, time-boxed investigations to explore uncertain areas. If a spike reveals high uncertainty, that finding becomes a risk item.
Documenting Risk Items
When a risk is identified, it should be treated with the same rigor as a feature. It needs a clear description, an impact rating, and a probability rating. In many frameworks, risks are assigned a severity score derived from these two factors. This helps the team decide whether to accept the risk, mitigate it, or transfer it.
For example, a risk might be described as “Potential latency issues in the new payment gateway integration.” The impact is high because it blocks revenue, while the probability is medium based on previous vendor documentation. This specific entry can then be added to the backlog as a task to investigate latency limits.
Mitigation Strategies for Sprints ⚔️
Once risks are identified, the next step is action. Mitigation strategies vary depending on the nature of the risk and the current state of the project. The key is to integrate these actions into the daily workflow rather than treating them as side projects.
Technical Mitigation
Prototyping: Build a minimal version of a complex feature to validate assumptions before full-scale development.
Refactoring: Regularly dedicate capacity to improving code quality. This reduces the risk of future bugs and makes the system more resilient.
Automated Testing: Increase coverage for critical paths. Automated tests catch regressions early, reducing the risk of deploying broken code.
Documentation: Keep architecture diagrams and API contracts up to date. This reduces the risk of integration errors between different team components.
Process Mitigation
Pairing: Use pair programming for high-risk code areas. This increases code quality and distributes knowledge, reducing the risk of single points of failure.
Definition of Ready: Ensure stories are well-understood before work begins. This reduces the risk of rework caused by ambiguous requirements.
Time Boxing: Limit the time spent on tasks. This prevents diminishing returns and forces the team to prioritize the most critical aspects of a feature.
Continuous Risk Monitoring and Review 🔄
Risk is dynamic. A low-probability risk today could become a high-probability risk tomorrow if the environment changes. Therefore, continuous monitoring is essential. This does not require new tools or heavy reporting, but rather a shift in how meetings are conducted.
Integration into Ceremonies
Different ceremonies serve different monitoring purposes:
Daily Standup: Briefly mention blockers or new risks that have emerged since the last update. This keeps the immediate focus on current impediments.
Sprint Planning: Review the risk backlog. Are any risks becoming more urgent? Do we need to add new mitigation tasks to this sprint’s capacity?
Sprint Review: Demonstrate how risks were handled. Show the results of prototypes or testing improvements. This validates that mitigation efforts are working.
Sprint Retrospective: Analyze the effectiveness of risk responses. If a risk materialized, why was the mitigation insufficient? What can be improved for the next cycle?
Visualizing Risk
Visual tools help maintain awareness without creating administrative overhead. A simple risk burn-down chart can track the number of open high-severity risks over time. If the line is flat or rising, it indicates that the team is not keeping up with emerging threats.
Another effective method is a radar chart that plots risks across categories like security, performance, and usability. This provides a quick snapshot of where the project is vulnerable. These visuals should be displayed in the team workspace so that anyone walking by understands the current risk profile.
Common Pitfalls in Agile Risk Handling
Even with a solid framework, teams often stumble into traps that undermine risk management efforts. Recognizing these pitfalls is the first step toward avoiding them.
Ignoring Low Impact Risks: Dismissing risks as “low impact” without monitoring them. Low impact risks can compound over time to become critical issues.
Over-Mitigation: Spending too much time and resources on risks that are unlikely to happen. This reduces the capacity for delivering actual value.
Siloed Information: Keeping risk data in a private document. If the team doesn’t know about the risks, they cannot respond to them.
Blame Culture: Punishing team members for reporting risks. This discourages transparency and leads to hidden problems.
Confusing Problems with Risks: A problem is something that has already happened. A risk is something that might happen. Treating them the same way leads to reactive fire-fighting instead of proactive planning.
Integrating Risk into Definition of Done
The Definition of Done (DoD) is a checklist of criteria that must be met before a user story is considered complete. Including risk criteria in the DoD ensures that quality and safety are not compromised for speed.
Examples of risk-related DoD criteria include:
Code has been reviewed by at least two team members.
All automated security scans have passed with no critical vulnerabilities.
Performance benchmarks have been met for the new feature.
Documentation has been updated to reflect the changes.
Rollback procedures have been tested and documented.
By embedding these checks into the DoD, the team ensures that every increment of software is delivered with a baseline level of safety. This prevents technical debt from accumulating in a way that threatens the project’s stability.
Organizational Culture and Risk
Risk management is not just a process; it is a cultural attribute. If the organization rewards speed over safety, the team will inevitably cut corners. Leadership plays a crucial role in setting the tone.
Leaders should:
Model Vulnerability: Admit when they do not know the answer. This encourages the team to speak up about uncertainties.
Protect the Team: Shield the team from external pressure to deliver prematurely. Allow them the space to manage risks effectively.
Invest in Training: Provide opportunities for the team to learn about risk identification and mitigation techniques.
Celebrate Early Detection: Recognize and reward team members who identify risks early, even if it delays a feature. This reinforces the value of caution.
Risk Categories and Mitigation Matrix
To assist in planning, teams can refer to a matrix that maps common risk categories to specific mitigation strategies. This table serves as a reference during planning sessions.
Risk Category | Potential Impact | Recommended Mitigation |
|---|---|---|
Technical Debt | Slower development, increased bugs | Allocate 20% of sprint capacity for refactoring |
Resource Availability | Bottlenecks, delays | Cross-train team members to cover critical roles |
External Dependencies | Blocked progress, integration failures | Use mocks or stubs to decouple development |
Scope Creep | Missed deadlines, budget overruns | Strictly enforce backlog prioritization |
Security Vulnerabilities | Data breaches, compliance issues | Integrate static analysis into CI/CD pipeline |
Market Changes | Feature becomes obsolete | Deliver minimum viable product early for feedback |
Measuring the Success of Risk Management
How do you know if your risk management is working? You need metrics that reflect the health of the project rather than just output. The following indicators provide insight into risk effectiveness:
Risk Burndown Rate: The rate at which risks are closed versus the rate at which new risks are identified.
Incident Frequency: The number of unplanned outages or critical bugs per sprint.
Rework Percentage: The amount of work that must be redone due to quality or requirement issues.
Stakeholder Confidence: Survey stakeholders on their perception of project stability and predictability.
Mean Time to Recovery: How quickly the team can restore service when a risk materializes.
Tracking these metrics over time allows the team to adjust their strategies. If the incident frequency rises, it may indicate that the current mitigation strategies are insufficient. If the risk burndown rate is low, the team may need to dedicate more time to proactive work.
Conclusion
Risk management in iterative software projects is an ongoing discipline that requires vigilance, transparency, and adaptability. It is not about predicting the future with certainty, but about building a system that can withstand uncertainty. By integrating risk identification into the backlog, mitigating issues within sprints, and monitoring progress continuously, teams can navigate complexity with confidence.
The ultimate goal is not a risk-free project, but a resilient one. When risks are managed well, the team can focus on delivering value rather than fighting fires. This approach leads to sustainable development, higher quality software, and satisfied stakeholders. Embracing risk as a natural part of the journey allows the organization to move forward with clarity and purpose.

