




カスタマージャーニーマッピングは、単純なスケッチから複雑でデータ駆動型の可視化へと進化しました。しかし、このプロセスにおける最も一般的な失敗要因は、単一の情報タイプに依存することです。数値のみで構築されたマップは共感を欠きます。物語のみで構築されたマップはスケールを欠きます。カスタマーエクスペリエンスを真正に正確に表現するためには、チームはジャーニーマップにおいて定性的データと定量的データのバランスを取らなければなりません。この統合により、行動と動機の包括的な視点が得られます。
これらの2つのデータストリームが統合されると、得られるインサイトは強固になります。数値は数千ものインタラクション全体で何が起きているかを明らかにします。物語はその行動がなぜ起こるのかを明らかにします。どちらかの側面を無視すると、理解の穴が生じ、戦略がずれ、最終的にカスタマーフリクションにつながります。このガイドでは、これら異なるデータタイプを、どちらのニュアンスも失わず、一貫した物語に統合する方法を詳述します。
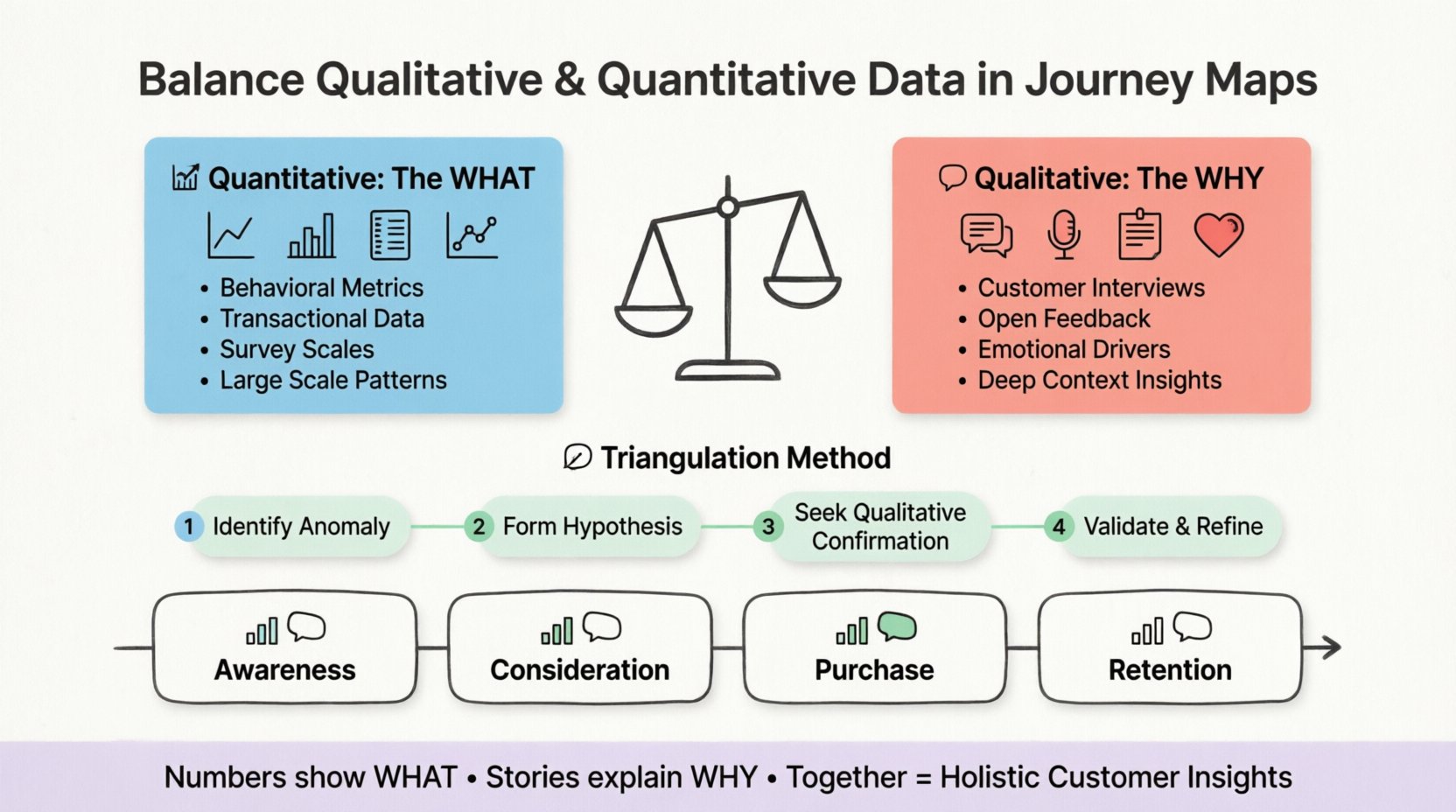
🧩 カスタマーサイトの二面性
これらのデータタイプを効果的にバランスさせるためには、まずそれぞれの異なる役割と限界を理解する必要があります。これらは競合関係にないのです。同じツールキットの中の補完的なツールなのです。
📈 定量的データ:何が起こっているか
定量的データは数値です。客観的で測定可能なものです。カスタマージャーニーの文脈では、このデータはシステムログ、取引記録、アンケートスケールから得られます。量、頻度、効率に関する質問に答えます。
- 行動指標:クリック率、セッション時間、カート離脱率、ページビュー数。
- 取引指標:平均注文金額、購入頻度、顧客生涯価値。
- アンケートスケール:ネットプロモーターサービス(NPS)、顧客満足度(CSAT)、顧客努力度(CES)。
定量的データの強みは、大規模な集団全体でパターンを特定できる点にあります。特定のステップで40%のユーザーが離脱する場合、それは問題の定量的なサインです。しかし、数値そのものでは摩擦の原因を説明しません。ボタンが小さすぎるのか、テキストが混乱しているのか、価格が予想外なのかを教えてくれません。ただ、障壁が存在するということだけを教えてくれるのです。
🗣️ 定性的データ:なぜそうなるのか
定性的データは記述的です。主観的で体験に基づくものです。このデータはインタビュー、オープンエンドのアンケート回答、サポートチケットの記録、ソーシャルメディアのコメントから得られます。感情、動機、認識に関する質問に答えます。
- 直接フィードバック:顧客インタビュー、フォーカスグループ、ユーザビリティテストのメモ。
- 非構造化テキスト:チャットログ、メールやり取り、レビューのコメント。
- 観察メモ:研究者が顧客が製品やサービスとどのようにやり取りしているかを観察するフィールド調査。
定性的データの強みは深さにあります。意思決定の背後にある感情的要因を明らかにします。ユーザーがなぜ迷ったのか、特定の機能がなぜ不満を引き起こしたのかを説明します。しかし、スケールがありません。数人のインタビューで深刻な問題が明らかになるかもしれませんが、それが10%か、10%のユーザーに影響しているかどうかを確認することはできません。
⚠️ バランスの欠如が歪んだマップを生む理由
ジャーニーマップが一方の方向に偏りすぎると、歪んでしまいます。こうした歪みを理解することで、マッピングプロセス中にチームが均衡を保つことができます。
🔢 純粋な定量化の罠
分析データのみで作成されたマップは、しばしばフローチャートのように見えます。タッチポイントやコンバージョン率は示しますが、人間的な文脈が欠けます。このアプローチは、行動が合理的で一貫していると仮定しています。
- 感情の喪失:高い離脱率が記録されているが、不満度は不明である。
- 文脈無視: アナリティクスはサポート通話の急増を示す可能性があるが、定性的な情報がなければ、チームはそれがバグのためか、マーケティングの約束が果たされなかったためか分からないかもしれない。
- 満足度よりも効率性を最適化する: チームはステップを減らすためにプロセスを簡素化するかもしれないが、その結果、ユーザーが安心感を得るために実際に価値を感じていた機能が無意識に削除されることがある。
💬 純粋な定性的分析の罠
インタビューとエピソードだけから構築されたマップはしばしば主観的である。それは広範なユーザー層ではなく、特定で声の大きいユーザー層の経験を反映しているだけである。
- 生き残りバイアス: インタビューはしばしば非常に満足しているか、非常に怒っているユーザーを引き寄せる。静かで大多数のユーザーは欠けている。
- サンプルサイズの問題: 5人のインタビューは5万人のユーザーを代表しない。優先順位は、インタビューされた特定の人物によって変化する可能性がある。
- ベンチマークの欠如: 数値がなければ、時間の経過に伴う進捗を追跡することは不可能である。ユーザーが不満であることは分かるが、修正が実際に不満を減らしたかどうかを測定できない。
🔗 データストリームの統合
統合とは、データを単一のスプレッドシートにマージすることではない。数値が物語を裏付け、物語が数値に人間性を与えるように物語を織りなすことが目的である。以下は、これらの入力を統一するためのフレームワークである。
📋 データタイプの比較
| 特徴 | 定量データ | 定性データ |
|---|---|---|
| 主な質問 | どれくらい?何個? | なぜ?どのように? |
| 形式 | 数値、チャート、グラフ | テキスト、音声、動画、引用文 |
| 範囲 | 大規模なサンプルサイズ | 小規模で深いサンプルサイズ |
| 強み | トレンドやパターンを特定する | 動機や感情を特定する |
| 弱み | 文脈とニュアンスが欠けている | 統計的有意性が欠けている |
| 最適な使用法 | 仮説のスケールでの検証 | 仮説の生成と感情の探求 |
🛠️ 三角法アプローチ
データのバランスを取るために、三角法アプローチを使用してください。これは、ある結論を確認するために複数の視点から証拠を集めるということです。
- 異常を特定する:定量データを使って統計的外れ値を見つける。例えば、チェックアウトページでの50%の離脱率。
- 仮説を立てる:数値に基づいて理由を提案する。たとえば、フォームが長すぎるか、送料が隠されている可能性がある。
- 定性的な確認を求める:ユーザーインタビューを行うか、その特定のチェックアウトステップに関連するサポートチケットを確認する。
- 検証または修正: ユーザーが送料が予想外だったと確認すれば、仮説は検証されたものとなる。もしユーザーが送料について何も言わなければ、仮説は誤りであり、定量データが誤解を招く可能性がある(たとえば、決済ゲートウェイがクラッシュした可能性がある)。
🗺️ デュアルデータによる段階のマッピング
顧客ジャーニーはほとんど線形ではない。認知からリテンションまでの複数の段階から構成される。各段階で効果的に機能させるには、データタイプの重み付けが異なる必要がある。
👀 認知と発見
この段階では、トラフィックの量は高いが、意図は多様である。
- 定量的: トラフィックの出所、バウンス率、ランディングページでの滞在時間。
- 定性的: 検索意図分析、ソーシャルセンチメント、第一印象のフィードバック。
- 統合: アナリティクスを使って、どのチャネルがトラフィックを生み出しているかを確認する。インタビューを使って、実際にコンバートしたユーザーと離脱したユーザーの間に、どのメッセージが共感を呼んだかを理解する。
🤔 検討と評価
ここでは、ユーザーが選択肢を比較する。摩擦はしばしば微細である。
- 定量的: プロダクトページの閲覧数、価格ページでの滞在時間、比較ツールの利用状況。
- 定性的: FAQのインタラクション、リサーチ中のカスタマーサポート問い合わせ、競合レビュー。
- 統合:価格ページへのアクセス数が多いということは関心があることを示している。定性的なフィードバックから、価格構造がわかりにくいのか、あるいは価値提案が明確でないのかが明らかになる。
💳 購入と取引
ここが転換の重要なポイントであり、離脱がコストとなる。
- 定量的:コンバージョン率、カート離脱率、フォーム内のエラーレート。
- 定性的:ユーザビリティテストの記録、チェックアウト時の不満の兆候、信頼の指標。
- 統合:エラーレートが低くても離脱率が高い場合、定性的なデータから、技術的なエラーではなく信頼性の問題が原因であることが明らかになるかもしれない。
🤝 購入後とリテンション
この段階が長期的な忠誠心を決定する。
- 定量的:再購入率、離脱率、更新日。
- 定性的:カスタマーサポートの感情、レビューの感情、ネットプロモータースコア。
- 統合:高い離脱数は、製品が約束を果たせなかったかどうかを理解するために、退職面談のデータと併用する必要がある。
🕳️ 一般的な分析の罠を避ける
良い意図を持っていても、データを統合する際にバイアスが入り込むことがある。これらの罠に気づいておくことで、ジャーニーマップの整合性が保たれる。
🚫 確証バイアス
チームはしばしば既存の信念を支持するデータを探してしまう。リーダーシップが特定の機能が人気があると信じている場合、その機能がわかりにくいという定性的なフィードバックを無視して、定量的な利用統計を優先するかもしれない。逆に、チームが特定のプロセスを嫌っている場合、肯定的な利用データを無視して、否定的なインタビューだけを選び取ってしまう。
- 緩和策:ジャーニーマップ作成前に、中立的なレビュアーを割り当ててデータを分析させる。肯定的・否定的なデータポイントの両方が反映されるようにする。
🚫 「声の大きい少数派」の罠
定性的なデータは、声を上げる時間を取るユーザーから多く得られる。こうしたユーザーはしばしば外れ値である。彼らに過度に依存すると、マップが歪んでしまう。
- 緩和策:常に定性的な引用を定量的な頻度と照合する。1人のユーザーの不満が、分析で見られるトレンドを反映しているのか?
🚫 データの島嶼化
マーケティングチームは1つのデータセットを持ち、サポートチームは別のデータセットを持ち、プロダクトチームは3つ目のデータセットを持っています。これらの情報の断片化が解消されない場合、ジャーニーマップは断片化してしまいます。
- 緩和策:中央のリポジトリまたはデータガバナンスポリシーを設立する。マッピングを開始する前に、すべての関係者が同じ原始データソースにアクセスできるようにする。
🚀 統合されたインサイトで前進する
データのバランスを取る目的は完璧さではなく、進歩です。ジャーニーマップは動的な文書です。新しいデータが得られるたびに継続的に更新が必要です。
🔄 持続可能なフィードバックループの構築
バランスを維持するためには、このプロセスを定期的な業務に組み込む。
- 四半期ごとのデータ監査:四半期ごとにジャーニーマップをレビューする。定量的指標は変化しているか?以前の仮説と矛盾する新しい定性的フィードバックは出現したか?
- ステークホルダー・ワークショップ:プロダクト、マーケティング、サポートチームを一堂に集めてマップをレビューする。異なる部門は異なるデータポイントを見ている。それらの統合された視点が二重アプローチの正当性を裏付ける。
- リアルタイムアラート:重要な定量的変化に対して自動アラートを設定する。指標が急上昇した際には、直ちに原因を理解するために定性的な調査を開始する。
📊 マップの影響を測定する
バランスの取れたマップが機能しているかどうかはどうやって知るか?マップに基づいて行われた意思決定の結果を測定することで知る。
- 摩擦の低減:データで特定された摩擦ポイントに対処した後、離脱率は低下したか?
- 感情の改善:インタビューで見つかった感情的な痛みポイントに対処した後、NPSやCSATスコアは向上したか?
- 意思決定の迅速化:チームは「何が起きているか」を議論する時間は減り、「何をすべきか」を決める時間が増えたか?
🛡️ データ品質の確保
データの種類をバランスさせる際には、「ゴミが入ればゴミが出る」は二重に当てはまる。どちらのデータストリームにも品質が低いと、全体の取り組みが崩れてしまう。
🔍 定量的入力のクリーニング
トラッキングの正確性を確保する。ピクセルが欠けている、またはトラッキングコードが壊れている場合、数値は嘘になる。データがボットトラフィックや内部テストではなく、実際のユーザー行動を反映していることを検証する。
🗣️ 定性的入力のクリーニング
インタビューが誘導的にならないようにする。答えを暗示する質問を避ける。オープンエンドの回答を分析する際は、一貫したコードフレームワークを使用し、テーマを客観的に特定する。
🎯 最良の実践の要約
両方のデータタイプを尊重するジャーニーマップを作成するには、自制心が必要です。チームが統計と同じくらい物語の価値を認識する必要があります。整合性を確保するためのチェックリストを以下に示します。
- 目的を定義する: 効率性のためにマッピングしているのですか、それとも共感のためにですか?データの比率をそれに応じて調整してください。
- まずは定量データから始めましょう:数値を使って、調査が必要な問題領域を見つけましょう。
- 次に定性データを追加しましょう:物語を使って、問題領域の根本原因を理解しましょう。
- 継続的に検証しましょう:マップを事実ではなく仮説として扱いましょう。新しいデータが入るたびにそれを更新してください。
- 明確に可視化しましょう:マップを使って、数値と物語が交差する場所を示しましょう。両者の矛盾を隠さず、発見の場として強調してください。
正しく行われれば、ジャーニーマップは唯一の真実の源になります。経営陣と現場の間の溝を埋め、分析ダッシュボードとカスタマーサポートデスクをつなぎます。ジャーニーマップにおいて定性的データと定量的データをバランスよく組み合わせることで、組織は単に効率的であるだけでなく、本質的に理解される体験を構築できるのです。

